当英伟达把"手机内存"塞进服务器,一场关于能效的军备竞赛已经打响。SOCAMM并非横空出世的技术奇迹,而是AI算力需求演化催生的必然产物。它代表了一种从“唯带宽论”到“均衡设计”的务实转向,其投资逻辑根植于一个确定性的趋势:AI推理和边缘计算的规模化部署。
说实话,第一次听到SOCAMM这个词吧,我还以为是某个硅谷新创公司的融资代号,查了资料,也看了美光的介绍,才知道这是一个专门为AI而创造的内存产品,个人感觉,这很有可能给内存市场带来新的冲击。
这可不是危言耸听。如果你留意AI基础设施的投资机会,SOCAMM极有可能就是未来最值得重新去评估的技术变量,它正在使移动端和数据中心的边界变得模糊,也极有可能重塑内存三强(三星、SK海力士、美光)的竞争格局。更关键的是,一个长期被忽视的市场空白被它精准地找到了,当AI从模型训练的军备竞赛迈入大规模推理部署的持久战时,算力基础设施的瓶颈不再仅仅是单纯的芯片算力,而是悄然转变为内存架构的能效比了。一、被忽视的能耗黑洞:为什么SOCAMM的崛起是必然?
训练GPT-4级别的模型,算力卡(GPU)那肯定是很费钱的东西,但真正让数据中心运营者发愁的,通常是内存系统的功耗,传统DDR5RDIMM在满负荷运行的时候,单条功耗能达到10-15W,一个配备512GB内存的AI服务器节点,内存这部分就能消耗上百瓦的电力。更麻烦的是,AI推理工作负载(也就是模型真正"干活"的时候)需要内存持续高频率运行,这种"电老虎"特性在规模化部署后,会直接吃掉利润表。曾经了解过某头部云厂商的内部数据,它那个AI集群的电费在运营成本里的比例,从两年前的15%涨到快30%了,内存功耗是排在GPU后面的第二大项。这就是SOCAMM出现的背景——它用"降本增效"的朴素逻辑,解决了AI推理时代的痛点。HBM(高带宽内存)靠着和GPU的2.5D3D封装集成,提供了特别高的带宽,是AI训练的必需东西,不过它的弊端也很明显,成本特别高(大概是同等容量DDR5的5倍),供应受到限制(先进产能被少数大公司垄断),而且形态固定(焊在GPU旁边,不能扩展。这就出现一个尴尬情况,对于那些得处理海量上下文(像长文本分析、多模态推理这类)、但其实不需要HBM极致带宽的AI推理工作负载,市场上缺少一种在容量、成本、功耗和灵活性方面能取得平衡的解决方案。SOCAMM应运而生。它基于LPDDR5X芯片(对,就是旗舰手机用的那种低功耗内存),通过模块化设计解决可维护性问题,与此同时把功耗砍掉三分之二,成本约为HBM的14。英伟达在GB300平台上率先采用,不是因为它喜欢尝鲜,实在是被逼无奈:在十万卡集群的规模下,内存功耗每降低1瓦,一年就能省下数百万美元电费。下一代AI应用朝着能自己做复杂任务、长时间保存记忆和状态的代理型AI方向发展,不再局限于单次问答,这类应用要求系统不要同时维持数百万甚至上亿个Token的活跃状态,这对内存容量和能效提出了史无前例的要求。单一的HBM在容量和成本方面都很难支撑,而且传统DDR5内存的带宽和能效还成了瓶颈,SOCAMM基于低功耗的LPDDR5X芯片,功耗能低到传统DDR5RDIMM的三分之一,与此同时通过模块化设计提供TB级别的可扩展容量,正好符合代理式AI对短期、大容量、高能效内存的需求。最初,SOCAMM被看作是英伟达给它的GraceCPU服务器平台定制的解决方案。可是,最近产业上的动态显示,它正在很快地打破单一厂商的生态壁垒。据《韩国经济日报》等好几个媒体报道,AMD和高通正在积极评估给他们的AI服务器芯片引入SOCAMM内存模组。更值得关注的是,AMD跟高通考虑的设计版本,在集成电源管理芯片(PMIC)这些方面跟英伟达版本有差别,这意味着SOCAMM正在朝着一个更开放、能定制化的行业标准发展。一旦形成多巨头支持的生态,它的市场潜力就会从只跟着单一客户,扩展到整个AI推理和边缘计算芯片市场,二、技术拆解:为什么SOCAMM能同时做到"小、快、省"
SOCAMM全称SmallOutlineCompressionAttachedMemoryModule,直译过来是"小型压缩附加内存模块"。名字很拗口,但设计思路很巧妙。传统的LPDDR内存得焊在主板上,坏了就要换整块板,数据中心根本没法接受这种维护方式,SOCAMM用了类似CAMM(CompressionAttachedMemoryModule)的螺丝固定加上金手指压缩连接的方案,做到了可拆卸更换,与此同时还保持着LPDDR5X的高带宽特性。- 尺寸:14×90mm,只有标准RDIMM的三分之一,主板空间利用率大幅提升
- 带宽:2.5倍于同容量DDR5RDIMM,满足AI模型对内存吞吐的饥渴
数据中心的电费担忧直接就缓解了,因为耗电量大概是DDR5RDIMM的三分之一-容量,单条最多192GB,已经够覆盖大部分推理场景的需求JEDEC正在推进的SOCAMM2标准(JESD328)还会加入SPD(串行存在检测)和更严格的可靠性认证,这意味着它正在从"英伟达专用方案"向通用服务器标准演进。三、产业博弈:三强争霸与供应链的权力重构
现在内存市场里,三星、SK海力士、美光这三家加起来占了超过95%的份额,不过SOCAMM要是崛起了,可能会让这场马拉松有变化。SOCAMM的核心是先进的LPDDR5XDRAM芯片,这决定了全球存储三巨头是毋庸置疑的主战场。目前竞争呈现白热化:靠着自己在最先进1c纳米制程上领先的良率,三星电子已经抢先拿到了英伟达2026年SOCAMM2订单的过半份额(大概1000亿GB),确立了早期市场领导者的地位,这也就表明,在性能差距不大的初期竞争当中,先进制程带来的成本和产能优势是核心的胜负关键。SK海力士与美光,SK海力士预计会拿到大约600-700亿GB的订单,排在后面,美光作为首批量产的厂商,它的技术路线很明确,通过1γ制程来进一步降低功耗,随着AMD、高通这些新客户加入,订单来源会变得多元化,第二梯队追赶的空间挺大的。SOCAMM可不是简单的芯片堆叠,它是包含了定制PCB、组装和测试的完整模组,这就提升了产业链中游的附加值。传统模组厂,像江波龙这类公司已经宣布和头部客户一起联合开发,并且成功点亮了SOCAMM产品,很有可能靠着自己灵活的客户响应还有系统集成能力,在定制化市场分到一份好处。封装和PCB供应链方面,SOCAMM独特的压缩连接(CAMM)设计以及高速信号的要求,对封装基板和高端PCB有了新的需求,这会给相关细分领域的龙头企业带来新的增长曲线。英伟达现在肯定是核心驱动力,打算在它的Rubin、VeraRubin等下一代AI平台里部署最多80万组SOCAMM模组。不过,更有想象力的是AMD、高通还有未来更多服务器CPU和AI加速器厂商会采用它。这样一来SOCAMM就会从可选配件变成主流配置,直接把需求给引爆咯。四、投资视角:机会在哪里,风险是什么
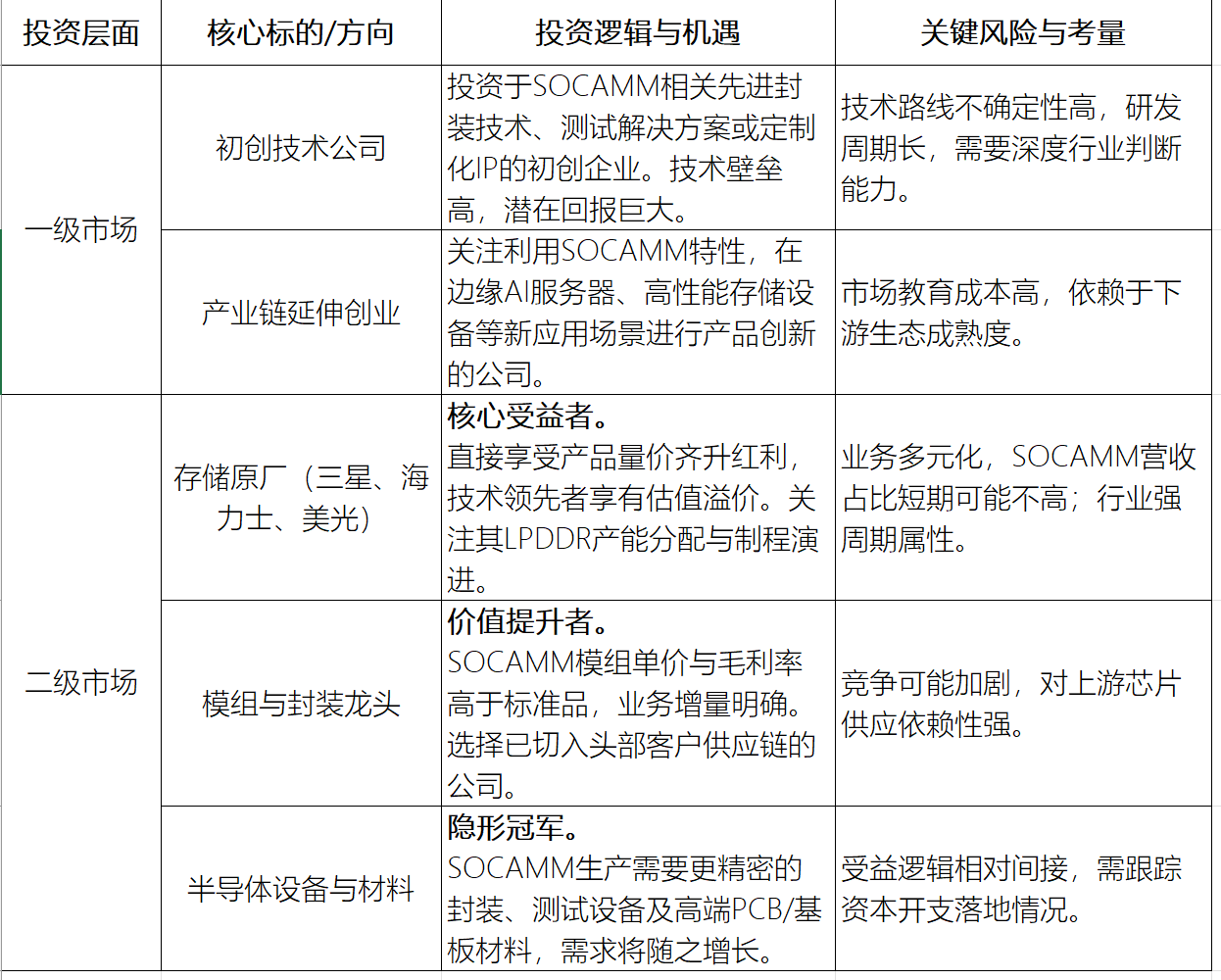
站在当下,SOCAMM相关的机会可以从三个维度梳理:
2)需要警惕的风险
技术发展和被替代的风险,存储技术更新换代特别快,得留意HBM成本降低、下一代DDRLPDDR标准,还有其他新型内存(像CXL)对SOCAMM市场定位可能产生的冲击。生态拓展没达到预期,SOCAMM成功的关键在于从英伟达出圈,如果AMD、高通这些厂商导入的进度比较慢或者最后选了替代方案,那就会严重限制它的市场空间。行业有周期性波动,全球DRAM市场是比较有强周期性的,现在行业库存处在历史低位,不过大规模的资本开支(像三星打算投入超130亿美元去扩产),未来可能会让供需出现逆转,就会影响产品的价格和利润。存储芯片是全球分工协作的典型例子,地缘政治和供应链风险存在,地缘局势变紧张或许会冲击整个供应链,与此同时,AI芯片对高带宽内存以及先进DRAM的供应优先级不断提升,已经慢慢挤占手机等别的终端领域的产能空间,这类资源分配的博弈正在加大行业的不肯定性。五、一场关于"能效比"的范式转移
写这篇文章的时候,我一直在琢磨,为啥是现在,LPDDR内存老早就有,模块化设计也不是啥新玩意儿,那为啥SOCAMM能在2025年一下子就成了焦点。答案可能在于AI工作负载的迁移。当行业焦点从"训练大模型"转向"部署大模型",从"算力堆砌"转向"成本优化",内存系统的能效比就变成了硬约束。SOCAMM恰好卡在这个转折点,用移动芯片的能效优势,解决数据中心的功耗痛点。对于投资者而言,可不只是盯着美光、三星、SK海力士的股价涨跌,更关键的是得明白这么个趋势,AI基础设施的创新,正从算力中心主义往系统能效主义转变,内存、散热、电源、网络,这些以前的配角现在正有着前所未有的战略重要性。当手机和消费电子的技术红利朝着数据中心那边转移的时候,咱们会看见更多跨界的新奇东西,去找到这些技术转移的早期信号,很有可能就是未来两年AI基础设施投资能得到关键超额收益的地方。关于作者:我是一名专注于科技投资领域的独立研究者。我的分析基于对产业链的长期跟踪、财报数据挖掘以及技术演进路径的交叉验证。我坚信,在AI与物理世界加速融合的时代,从底层技术和供应链中发现的洞见,比追逐市场情绪更有价值。本网站所有文章均为我的个人原创研究笔记,旨在记录思考,并与同道者交流。
评论