DeepSeek V4的三次解耦:架构、定价权与中国芯片突围
DeepSeek V4,就是中国AI打造的一件全新反击武器,而且是开源的。
它不需要摧毁所有对手,它的存在本身就已经打破了封锁的垄断。封锁的前提,是让对方手无寸铁。当一件能跑在国产芯片上、性能对标顶尖模型的开源大模型诞生时,“封锁能否阻断中国 AI” 这个问题,已经不再是需要回答的问题。
2025年1月,DeepSeek R1以一种几乎戏剧性的方式闯入全球AI视野:用远低于同行的算力,训练出足以媲美顶尖模型的推理能力。那一周,英伟达股价单日跌掉近600亿美元市值,硅谷的群聊里充满了惊慌。
然后,来到了2026年4月。
没有新品发布,没有高调的论文,甚至有媒体报道核心人员离职、新模型跳票。就在外界开始怀疑"R1是不是昙花一现"的时候,V4出现了。

◆ ◆ ◆
一、V4到底做了什么
在讲意义之前,先讲清楚V4的技术事实。
V4发布了两个版本。V4-Pro是面向复杂编码和多步骤智能体任务的大模型,API定价为每百万输入token 1.74美元、输出3.48美元——这大约是OpenAI和Anthropic同类产品的三分之一到五分之一。V4-Flash是轻量版,输入仅0.14美元/百万token,是目前市面上最便宜的顶级模型之一。
两个版本都支持100万token的上下文窗口——这个数字意味着你可以把《指环王》三卷加《霍比特人》一口气全部塞进去,让模型通读后再回答问题。
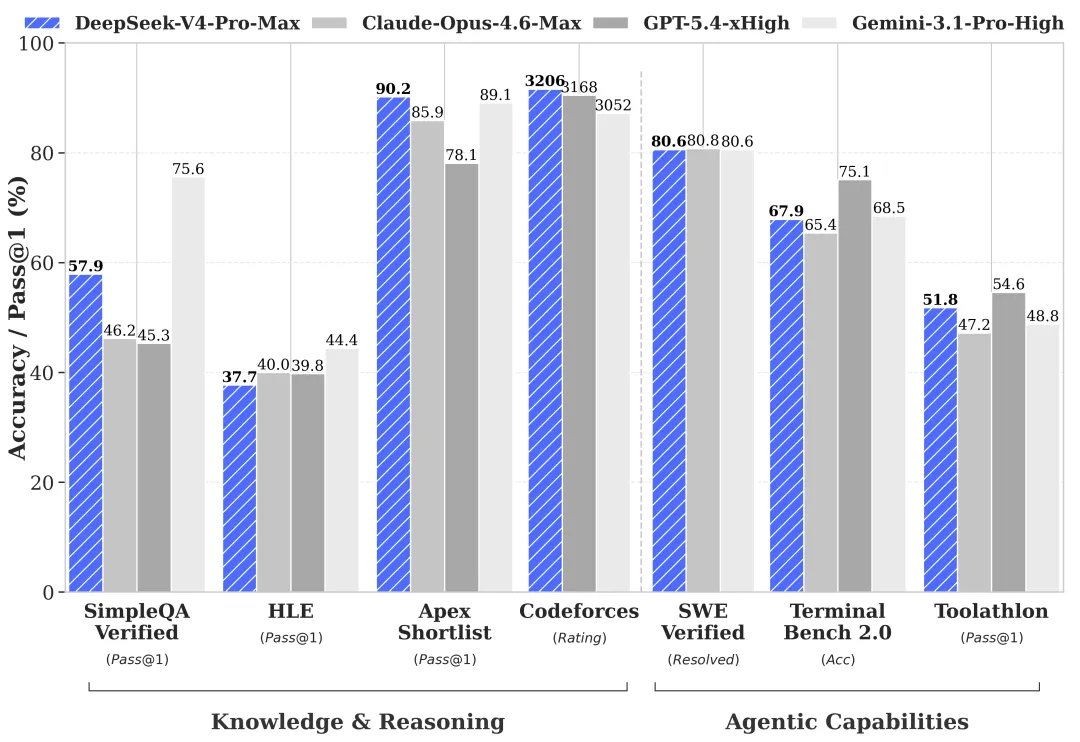
这些都是好成绩。但如果你只盯着跑分,你就错过了这个故事真正重要的部分。
◆ ◆ ◆
二、架构创新,把只能“烧算力堆上下文”的路子打开了一个小缺口
长上下文一直是AI行业的隐形暗礁。
理论上说,让模型能处理更长的文本很简单:把上下文窗口调大就行了。但“注意力机制”——模型理解文本各部分之间关系的核心机制——有一个残忍的数学性质:计算成本随输入长度的平方增长。
换句话说,上下文窗口从10万token扩展到100万token,计算量不是变成10倍,而是接近100倍。这就是为什么尽管Gemini很早就宣传“百万上下文”,但真正使用时的成本让大多数开发者望而却步。
V4的创新在于它改变了注意力机制的逻辑。它让模型学会“选择性注意”:不再把整段上下文里每一个早期token都当成同等重要的信息来处理,而是压缩旧信息,优先关注当前最可能相关的部分,同时保留"附近文本"的完整细节以防遗漏关键内容。
这相当于什么?
想象你在复习一本厚厚的专业教材。传统注意力机制的读法是:每次你看到一个新段落,都要把前面所有内容重新在脑子里过一遍,越往后越累。V4的读法是:你记得每章的核心要点(压缩存储),但对你刚刚看过的几页保持鲜活的记忆(本地完整保留)。
结果是:在100万token的上下文中,V4-Pro的计算量仅为上一代V3.2的27%,内存使用量降至10%。V4-Flash更激进,计算量和内存使用量分别只有10%和7%。
这个数字的工程意义是:长上下文不再是一个“烧钱才能用”的高端功能,而是一个有可能下沉到普通开发者的基础能力。一个能读完整个代码库的AI编程助手、一个能消化几百篇文献而不遗忘早期内容的科研Agent——这些需求在过去要么买不起,要么根本跑不了。V4让这件事的成本数量级发生了变化。
不再依赖“买更多算力”来换取更长的上下文,而是从数学结构上重新设计。
◆ ◆ ◆
三、开源价格战,把闭源模型的定价权给动摇了
AI行业有一个长期存在但鲜少被正面讨论的权力结构:定价权。
OpenAI、Anthropic、Google——这些公司掌握着顶级模型,也因此掌握着向整个开发者生态定价的权力。你想用最好的模型,就得接受他们的价格。这不是垄断,但这是一种结构性优势:在没有真正可替代的竞争对手之前,顶级闭源模型可以持续收取溢价。
DeepSeek正在系统性地侵蚀这个优势。
V4-Pro的输出定价是3.48美元/百万token。而Anthropic的Claude Opus类产品,同等级别的输出定价在每百万token 15美元以上。V4-Flash更是把"顶级模型调用"的价格打到了0.28美元/百万token的水平。
并且,V4是开源的。这意味着有足够资源的公司完全可以下载权重、自行部署,完全绕开DeepSeek的API,不付任何API调用费用。
对于正在决策“用哪家模型构建产品”的开发者和公司来说,这个组合拳的逻辑非常清晰:
- ◆如果你需要顶级性能且对数据隐私要求高:下载V4权重,自行部署,成本主要是算力
- ◆如果你需要快速调用且对成本敏感:用V4-Flash API,价格是竞争对手的十分之一以下
- ◆如果你需要做Agent类任务(编码、多步骤规划):V4-Pro已经针对Claude Code、OpenClaw等主流框架专门优化
闭源模型的核心护城河之一,是“我的效果比你好,所以你得接受我的价格”。当开源模型的效果已经足够媲美闭源模型,这道护城河就开始有了裂缝。
这并不是说OpenAI、Anthropic就此岌岌可危。他们在产品体验、安全对齐、企业服务等方面仍有显著差距需要弥补。但有一件事是确定的:过去那种“闭源模型自动享有价格溢价”的时代,有可能结束。
AI定价权的天平,正在从“我有最好的模型”向“我有最好的产品体验+生态锁定”倾斜。
◆ ◆ ◆
四、从英伟达芯片上,向华为芯片迈出第一步
V4是DeepSeek第一款专门针对国产芯片(华为昇腾系列)进行优化的模型。
自2022年美国启动对华芯片出口管制以来,中国AI公司最大的焦虑之一是:英伟达H100、A100这些训练AI模型的核心芯片,正在变得越来越难以获得。中国公司能买到的,要么是降级版(H800、A800),要么是走各种灰色渠道。而美国政府还在不断收紧管制。
从理论上说,解决方案是“用国产芯片替代英伟达”。但这件事说起来简单,做起来极难。英伟达的护城河不只是芯片性能本身,更在于围绕CUDA(英伟达的编程框架)建立的庞大软件生态:几乎所有主流AI框架、优化工具、工程实践,都默认在英伟达的CUDA生态上运行。
换用华为昇腾芯片,不是换一块硬件那么简单,而是相当于从Windows换到一个全新的操作系统——你得把所有软件重新移植、重新调试、重新验证稳定性。这是一项工程量极其庞大的工作。
V4迈出了这一步。根据DeepSeek的技术报告,他们已经使用国产芯片来运行V4的推理环节(即用户实际调用模型时的计算过程)。华为也随即宣布,基于昇腾950系列的超级节点将直接支持DeepSeek V4。
同时,要注意,DeepSeek V4 的国产芯片适配范围远超华为一家。它实现了全球首例 “Day0 级” 全国产芯片适配,同时支持华为昇腾、寒武纪、海光、沐曦、摩尔线程、昆仑芯、平头哥、天数智芯共 8 家主流国产 AI 芯片。这意味着开发者现在有了一整套完全不依赖英伟达的部署选择。
这意味着什么?这意味着希望在自己机器上运行V4的企业或个人,现在有了一条清晰的国产硬件路径可以走。
当然,这里需要诚实地说清楚边界。清华大学计算机科学教授刘志远告诉《MIT科技评论》:DeepSeek目前可能只针对国产芯片适配了部分训练流程,报告并未说明所有关键的长上下文特征是否都已针对国产芯片适配。目前V4的主体训练,很可能仍然在英伟达芯片上完成。
这是迈出第一步,还没有彻底摆脱英伟达。
但DeepSeek已经给出了一个信号:V4未来的价格下降,被绑定到——华为昇腾950超级节点大规模出货——这件事上。这意味着如果华为的芯片供应如期落地,V4-Pro的调用成本还会进一步压缩。
这是中国AI产业政策与商业逻辑罕见地站在同一方向上的时刻:政府在推动去英伟达化(采购配额、禁令),DeepSeek有经济动机去降低成本(国产芯片更便宜),华为有商业动机去提供更好的昇腾支持——三方形成正向循环。
◆ ◆ ◆
五、对AI行业意味着什么?
以上三层解耦加在一起,描述的是一幅什么样的图景?
第一,AI基础设施正在走向碎片化多极格局,而不是一家独大。
过去三年,AI行业的隐含假设是:英伟达负责芯片,美国云巨头负责算力,OpenAI或Anthropic提供顶尖模型,全球开发者在这个统一基础上构建应用。这是一种高度中心化的技术栈。
DeepSeek V4是这个图景开始松动的证据之一。它在中国本土的算力上运行,用本土芯片推理,以开源方式提供给任何想要使用的人。这不是替代了上述格局,但它在旁边建了另一条路。
对于全球(尤其是中国和其他试图在AI上构建自主能力的国家)的开发者来说,他们第一次有了一个真实可用的、不依赖美国云基础设施的顶级模型路径。
第二,开源模型和闭源模型之间的性能差距,正在从代际差距收窄到接近平齐。
一年前,闭源模型在高难度任务上仍然领先开源模型一个明显的档次。今天,DeepSeek V4-Pro在多个基准上已经与顶级闭源模型打平。这个趋势说明:AI领域"开源滞后闭源一个身位"的规律,正在接近失效。
这对整个行业的商业逻辑影响深远。当开源模型的能力边界足够靠近闭源模型,闭源模型的护城河就只剩下:服务质量、安全对齐、产品体验、企业集成。技术能力本身,不再是安全的壁垒。
第三,AI能力的成本正在以超出大多数人预期的速度下降。
V4-Flash以0.28美元/百万token的价格提供顶级能力。V4-Pro的价格如果随着华为芯片大规模出货进一步下降,这意味着AI推理的成本在两年内可能下降一个数量级。
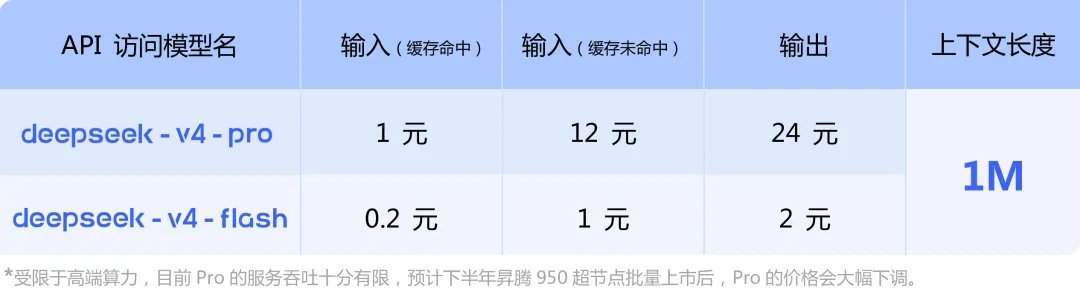
这对AI应用层是巨大的利好——更多边界场景变得经济可行,更多中小开发者能够进场。但对于那些依靠算力稀缺性来维持竞争优势的大模型公司来说,这是一个持续的压力:你必须不断找到新的差异化,而不能停留在我的模型最强这个护城河里。
◆ ◆ ◆
那些真正重要的东西,往往不在跑分表上
每次DeepSeek发布新模型,行业的第一反应都是盯着基准测试:它有没有超过GPT?它比Claude强多少?
这些问题当然有意义,但它们遮蔽了更重要的问题:这个模型的存在本身,改变了什么结构性的事情?
R1改变的是——高效能=高算力——这个等式,证明了聪明的训练方式可以用更少换来更多。
V4改变的是另外三个等式:长上下文=堆算力、顶级能力=闭源溢价、AI训练=依赖英伟达。每一个等式被打破,都是一块砖掉落,一道墙出现裂缝。
这是全球AI行业的基础假设,正在被重新检验。
而在那些跑分数字的背后,有一件事是确定的:今天开发者手里能用的工具,比一年前多了很多;今天能跑通的应用场景,比一年前便宜了很多;今天可以不依赖某一家公司或某一块芯片的选项,也比一年前多了很多。
这才是V4真正的意义。
评论